More and more projects are using Azure SQL as the database back-end for Sitecore (so long as they’re running Sitecore 8.2 and newer — if alignment to Sitecore official support guidance is important to you). This sets up a new class of performance considerations around Azure SQL, and I want to share one tuning option we learned while investigating high DTU usage for the Sitecore xDB “ReferenceData” database in a Sitecore 9 PaaS build. We wanted to off-load some of the work this “ReferenceData” database was doing, and investigations into which Azure SQL queries were causing the DTU spikes pointed to INNER JOINs between the ReferenceData.DefinitionMonikers and ReferenceData.Definitions tables.
Sitecore support pointed us in the right direction at this juncture, since the default DictionaryData was using AzureSQL for persistence — we should consider a store more suited to rapid key/value access. If this sounds like a job for Redis, you’d be correct, and fortunately Sitecore has an implementation that’s suited for this type of dictionary access in the Sitecore.Analytics.Data.Dictionaries.DictionaryData.Session.SessionDictionaryData class.
The standard Sitecore pipeline we’re talking about is the getDictionaryDataStorage pipeline and it’s used by Sitecore Analytics to store Device, UserAgent, and other key/value pair lookups. Here’s it’s definition:
The alternative we moved to is to use session state for storing that rapidly requested data, so we updated the DictionaryData node to instead use the class Sitecore.Analytics.Data.Dictionaries.DictionaryData.Session.SessionDictionaryData. For this Azure PaaS solution, it amounts to using Azure Redis for this work since that’s where the session state is managed. Here’s the new definition:
What this boils down to is the implementation in Sitecore.Analytics.DataAccess.dll of Sitecore.Analytics.DataAccess.Dictionaries.DataStorage.ReferenceDataClientDictionary was shown to be a performance bottleneck for this particular project, so changing to use the Sitecore.Analytics.dll with it’s Sitecore.Analytics.Data.Dictionaries.DictionaryData.Session.SessionDictionaryData aligns the project to a better-fit persistence mechanism.
We considered if we could improve upon this progress by extending the SessionDictionaryData class to be IIS in-memory regardless of the Sitecore session-state configuration; there would be no machine boundary to cross to resolve the (apparently) volatile data. Site visitors would require affinity to a specific AppService host in Azure, though, with this and it’s possible – or even likely — that Sitecore assumes this is shared state across an entire implementation. We talked ourselves out of seriously considering a pure IIS in-memory solution.
I think it’s possible we could improve the performance with the default ReferenceDataClientDictionary by tuning any caches around this analytics data, but I didn’t look into that since time was of the essence for this investigation and the SessionDictionaryData class looked like such a quick win. I may revisit that in the next iteration, however, depending on how this new solution performs over the long term.

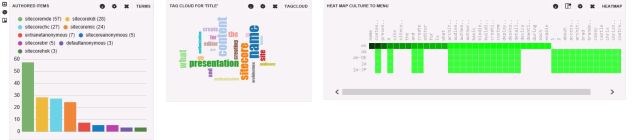
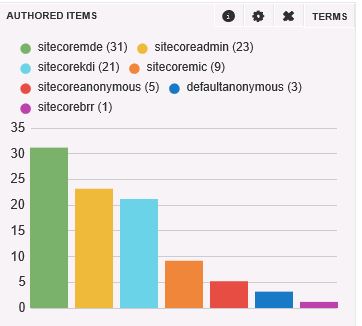

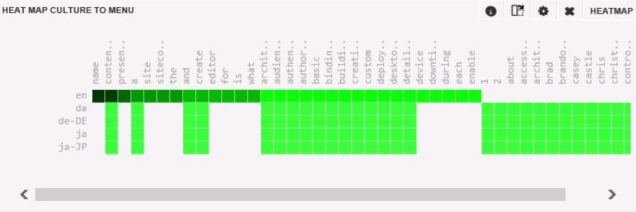
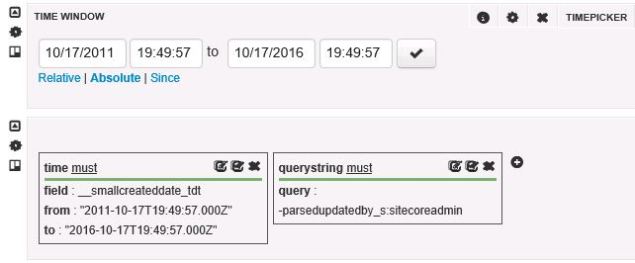
 This was all helpful information to the broader team working to determine why the records were remaining in MongoDB, but we needed a quick non-invasive solution.
This was all helpful information to the broader team working to determine why the records were remaining in MongoDB, but we needed a quick non-invasive solution.