Following on from Part 1 where I introduced what I’m up to here, let me jump right in to the other 5 Shenanigans for Solr + Sitecore:
Case 4 – The case of the default query crippler
- In this scenario, a customer’s Solr was straining to the breaking point and we tracked it down to a set of circumstances where Sitecore was using a default value for ContentSearch.SearchMaxResults (defaults to “” which is int.MaxValue which is 2,147,483,647) and flooding Solr with essentially unbounded queries. That default is downright dangerous. The query logs showed the queries using a rows value of int.MaxValue in rapid succession:
-
INFO Solr Query – ?q=associated_docs:(“\*A6C71A21-47B5-156E-FBD1-B0E5EFED4D33\*”)&rows=2147483647&fq=_indexname:(domain_index_web) INFO Solr Query – ?q=((_fullpath:(\/sitecore/content/Branches/XYZ/*) AND _templates:(d0321826b8cd4f57ac05816471ba3ebc)))&rows=2147483647&fq=_indexname:(domain_index_web)
- Solr will set aside some memory for the 2,147,483,647 results even if the dataset isn’t that large. I discussed a scenario like this in detail in this earlier post from 2018
- This write-up on Solr and “Large Number of Rows” speaks exactly to this scenario: https://risdenk.github.io/2018/10/21/apache-solr-out-of-memory-symptoms-and-solutions.html
Case 5 – The case of the bandwidth blowout
- Network bandwidth usage was off the charts for the customer we considered in this scenario. It took some digging, but we discovered it was due to a 23 GB Solr core being replicated across data centers. If one viewed the replication panel in the Solr UI, one could see the slow creep of the replication progress bar and it would never reach 100% complete before starting over.
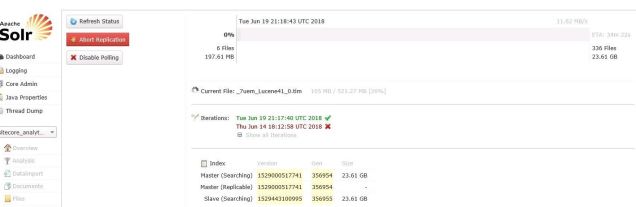
-
- There was additional supporting material such as Solr WARN messages etc:

-
- The network latency was too much for Solr master/slave replication to complete it’s work, but Solr kept on trying to move that 23 GB Solr core across the planet . . . and since this was the sitecore_analytics_index it was kept very busy by Sitecore. It all made for a feedback loop of frequent updates to the analytics index that couldn’t properly synchronize between data centers.
- For this particular scenario, we determined that there wasn’t a need to replicate the sitecore_analytics_index (it was consumed only by the CM environment which didn’t require the geographical scaling through Solr replication). We disabled the master/slave replication for that specific Solr core and the tidal wave of network traffic stopped. Case closed!
Case 6 – The case of the misguided, well-intentioned, administrator
- This scenario introduces a server administrator into the equation, and they actually cause more harm than good. The “optimize now” button in the Solr UI lured this administrator into clicking it without understanding the consequences:

- I posted about this in detail last year, so I won’t dig too far into it here, but the gist of this scenario illustrates how Solr internally organizes files and that there are questionable UI choices for that Optimize Now button. It makes it look like an easy way for one to improve Solr performance when — in reality — clicking that Optimize Now can be pretty expensive in terms of perf, especially for a volatile Solr core.
Case 7 – The case of the AppPool recycle-fest
- This scenario is one from a couple years ago, but it’s still relevant as a cautionary tale. For a long time, if Sitecore lost an active connection to Solr, the only option was to recycle the Sitecore AppPool. For a Solr server restart, or service restart, or even a transient network failure . . . Sitecore would need to run through the application initialization logic to reacquire Solr connectivity. In this specific case, there was a recurring network issue that interfered with Sitecore’s connectivity to Solr, so the customer scheduled IIS AppPool recycles every 15 minutes to ensure a fresh connection to Solr was available. This AppPool recycle-fest has terrible consequences for website performance as the site is constantly spending time on recycles and the related pipeline of events.
- This case highlights why there are now more elegant ways of handling this; I recently blogged about the IsSolrAliveAgent designed to solve this exact problem. There’s periodic logic to reconnect Sitecore with Solr now, and it’s important to appreciate why it’s there and — probably — why you may want to tune the default setting of every 10 minutes for your production environment.
That’s the 7 Shenanigans related to Sitecore and Solr from my talk earlier in October. It’s a fun paradigm for learning more about the overlaps of Sitecore and Solr and I hope it helps others to get more from their Sitecore + Solr technology stack!





 This was all helpful information to the broader team working to determine why the records were remaining in MongoDB, but we needed a quick non-invasive solution.
This was all helpful information to the broader team working to determine why the records were remaining in MongoDB, but we needed a quick non-invasive solution.