I’ve been involved with a lot of implementations of the new Sitecore Publishing Service lately and they’re starting to all run together. Before this episode fades too far into history, I want to record what I learned in case it’s useful to others (or myself!) at some point.
I’m going to skip all the preamble about .NET Core and how the new Publishing Service is designed to be lean and mean . . . that’s covered adequately in other places by now. I’ll jump right into this scenario where the Publishing Service was installed but all publishing operations would fail from the Sitecore Content Management server. It seemed like the CM wasn’t able to reach the .NET Core Publishing Service endpoint, but I confirmed the following were all in place:
- the host file included an entry for 127.0.0.1 pointing to Sitecore.Publishing.Service
- the Publishing Service was hosted through IIS with the Sitecore.Publishing.Service binding
- http://sitecore.publishing.service/api/publishing/operations/status responded with the expected JSON response “status 0” — so I concluded the service itself was OK
The Sitecore logs did have this cryptic “NotFound Not Found” exception, which was all I had to go on at first:
ERROR [Sitecore Services]: HTTP POST URL http://cm.website.com/sitecore/api/ssc/publishing/jobs/0/ItemPublish Exception System.AggregateException: One or more errors occurred. ---> Sitecore.Framework.Publishing.Client.Http.HttpServiceResponseException: The remote service encountered a problem processing the request: NotFound Not Found System.Net.Http.StreamContent at Sitecore.Framework.Publishing.Client.Http.JsonClient.<SendRequest>d__14.MoveNext() --- End of stack trace from previous location where exception was thrown ---
I envisioned a frustrated IIS server yelling “NotFound Not Found” — and, actually, that wasn’t so far from the truth. To discover the truth, I needed Fiddler.
There’s a ton of API calls going on when Sitecore CM servers interact with the Publishing Service, so Fiddler was the way to get a handle on all that communication. Sitecore has a KB article on how to wire up Fiddler to your Sitecore implementation, which is handy, and I put it to good use.
It was also necessary to dial up the verbosity of the Publishing Service instrumentation so we can see the full picture. One does this through the \config\sitecore\sc.logging.xml file under the Publishing Service installation. Set the filters like this . . .
<Filters>
<Sitecore>Debug</Sitecore>
<Default>Debug</Default>
</Filters>
. . . and restart the .NET Core service to make sure these take effect.
Fiddler can provide an overwhelming volume of information; imagine hundreds of entries like the following:
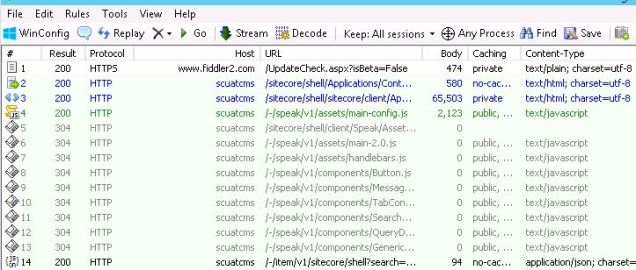
One technique is to carefully clear the Fiddler traces until just before you interact with the browser to perform your action, in my case just before I press the final Publish button in the Sitecore CM environment. I still had a lot of noisy Fiddler data to ignore, which I’ll remove from the screenshot below, but finally it revealed this red entry meaning failure.
And if you click on the details of that Fiddler trace you can inspect all the particulars. In this case it was pretty obvious the HTTP Verb Put wasn’t allowed here:
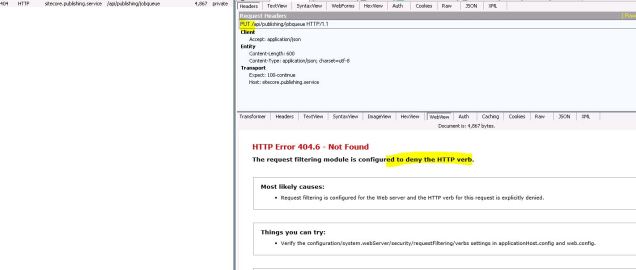
The fix was fairly complicated because there are good reasons for servers to block HTTP Verbs that aren’t in use, so we had to make the case PUT was required for the Publishing Service to work (and then add HTTP Verb blocking at a different layer of the implementation). We also found the OPTIONS HTTP verb was crucial for Publishing Service work using the same Fiddler technique described above. We ended up needing to permit both those 2 additional HTTP Verbs to enable proper Sitecore Publishing Service activity.
This isn’t really the final way to permit those verbs in a real production implementation, but it’s close enough for the purposes of this blog . . . check out the IIS Request Filtering options we needed to explicitly permit for this CM server to communicate to the Publishing Service running on the same VM host:
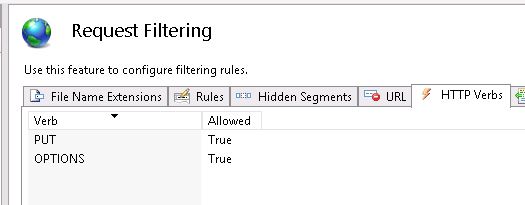
Sitecore’s had API service layers that depended on these HTTP Verbs for many years, so I shouldn’t be surprised to find the Publishing Service is also making use of them. I just never connected the two together. This customer, too, is very security conscious and features are thoroughly locked-down unless you explicitly enable them. This Sitecore 8 project isn’t otherwise using the Sitecore Sevices Client, for example, or the Item API. The good news is these PUT and OPTIONS exceptions are only internal to the system and not opened up outside to the public internet thanks to firewalls and other networking.
I will also note that we briefly explored the idea of customizing the HTTP Verbs the Publishing Service made use of . . . but you can imagine threading the needle of dependencies through that stack of libraries would be a very tough challenge.