A few days ago, I shared a graphic I put together to illustrate how Solr can be used to organize Sitecore “indexes” into Solr “cores” — this post has the complete graphic. I want to elaborate on how one sets Sitecore up to use these two approaches, and dig further into the details.
1:1 Sitecore Index to Solr Core Strategy
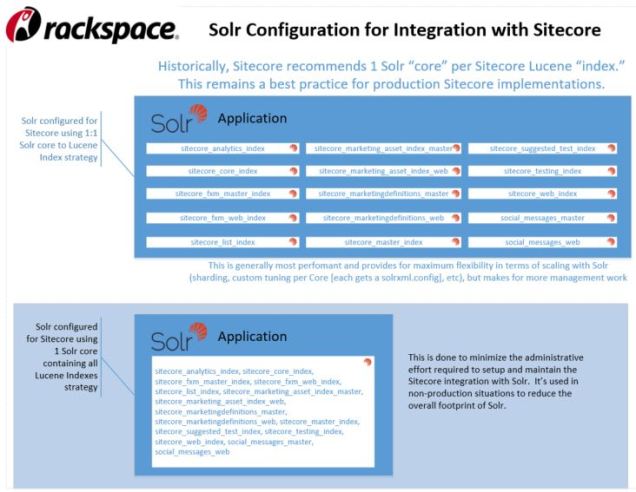
To start, here’s a visual showing the typical way Sitecore “indexes” are structured in Solr using a one-to-one (1:1) mapping:

This shows each of the default search indexes defined by Sitecore organized into their own cores defined in Solr. It’s a 1:1 mapping. This 1:1 strategy means each index has their own configuration (“conf”) directory in Solr, so seperate stopwords.txt, solrconfig.xml, schema.xml, and so on; it also means each index has their own (“data”) directory in Solr, so separate tlog folders, separate Segment files, etc.
This is the setup one achieves by following the community documentation on setting up Sitecore with Solr; specifically, this quote from that write-up is where you’re doing a lot of the grunt work around setting up distinct Solr cores for each Sitecore index:
“Use the process detailed in Steps 4-7 to create new cores for all the remaining indexes you would like to move to SOLR.”
Since this is the common strategy, I’m not going to go into more details as it’s straight-forward to Sitecore teams.
Kitchen Sink (∞:1 Sitecore Index to Solr Core) Strategy
Here is the comparable graphic showing the ∞:1 strategy of structuring Sitecore indexes in Solr; I like to think of this as the Kitchen Sink container for all Sitecore indexes, since everything goes into that single core just like the kitchen sink:

With this approach, a single data and configuration definition is shared by all the Sitecore indexes that reside in Solr. The advantages are reduced management (setting up the Solr replicationHandler, for example, requires updating 15 solrconfig.xml files in the 1:1 approach, but the Kitchen Sink would require only one solrconfig.xml file to update). There are significant drawbacks to consider with the Kitchen Sink, however, as you’re sacrificing scaling options specific to each Sitecore index and enforcing a common schema.xml for every index stored in this single core. There are plenty of reasons not to do this for a production installation of Sitecore, but for a crowded Sitecore environment used for acceptance testing or other use-cases where bullet-proof stability and lots of flexibility when it comes to performance tuning, sharding, etc is not necessary, you could make a good case for the Kitchen Sink strategy.
The only change necessary to a standard Sitecore configuration to support this Kitchen Sink approach is to patch the contentSearch definitions for the Sitecore indexes where the name of the Solr “core” is specified (stored by default in config files like Sitecore.ContentSearch.Solr.Index.Master.config, Sitecore.ContentSearch.Solr.Index.Web.config, etc). This is telling Sitecore which Solr core contains the index, but the actual name of the core doesn’t factor into the ContentSearch API code one uses with Sitecore. A patch such as the following would handle both the sitecore_master_index and the sitecore_web_index to organize into a Solr Core named “kitchen_sink:”
<configuration xmlns:patch="http://www.sitecore.net/xmlconfig/"> <sitecore> <contentSearch> <configuration> <indexes> <index id="sitecore_master_index" type="Sitecore.ContentSearch.SolrProvider.SolrSearchIndex, Sitecore.ContentSearch.SolrProvider"> <param desc="core">kitchen_sink</param> </index> <index id="sitecore_web_index" type="Sitecore.ContentSearch.SolrProvider.SolrSearchIndex, Sitecore.ContentSearch.SolrProvider"> <param desc="core">kitchen_sink</param> </index> </indexes> </configuration> </contentSearch> </sitecore> </configuration>
If you peek into the Solr Admin for the kitchen_sink core that I’m using, specifically the Schema Browser in the Solr Admin UI, it becomes clear how Sitecore uses a field named “_indexname” to represent the Sitecore index value. For this screenshot below, I’ve set the kitchen_sink core to contain two Sitecore indexes: sitecore_master_index and sitecore_web index:
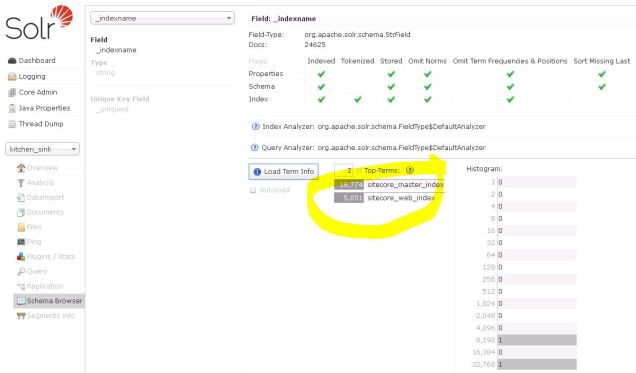
This shows us the two terms stored in that _indexname field, and that there are 18,774 for sitecore_master_index and 5,851 for sitecore_web_index. Even though the indexes are contained in the same Solr Core, Sitecore ContentSearch API code like this . . .
Sitecore.ContentSearch.ISearchIndex index =
ContentSearchManager.GetIndex(indexName);
using (Sitecore.ContentSearch.IProviderSearchContext ctx =
index.CreateSearchContext())
. . . doesn’t care whether all the Sitecore indexes reside in a single Solr “Core” or if they’re in their own following a 1:1 mapping strategy.
Caveats and Going In A Different Direction
There was a bug or two in earlier versions of Sitecore related to this, so be careful with early Sitecore 7.2 or Sitecore 8 implementations (and if you’re using Sitecore 7.5, you’ve got plenty of other things to worry about so don’t sweat a Solr Core organization strategy!).
I should also note that while this post is looking at combining Sitecore indexes into a single Solr Core for convenience and to reduce the management headaches of having 15 sets of Solr Cores to update etc, there are some implementations that go in the opposite direction. Consider a strategy like the following:

There may be circumstances where keeping Sitecore indexes in their own Solr Core — and even isolating them further into their own Solr implementation — could be in order. Solr runs in a JVM and this could certainly factor in, but there are other shared run-time resources that Solr sets aside for the whole Solr application.
I’m not familiar enough with these sorts of implementations that I want to comment further or recommend any course of action related to this right now, but it’s good to think about and consider with Solr tuning scenarios. I just wanted to share it, as it’s a logical dimension to consider given the two previous strategies in this post.
 causes people to think “something is wrong . . . red bad . . . must click now!”
causes people to think “something is wrong . . . red bad . . . must click now!”