Disclaimer: this is a journey of discovery and not a manual on database best practices for Sitecore Commerce 8.2.1.
You don’t see a lot of talk about disaster recovery and Sitecore Commerce — getting the regular implementation to work well is enough of a challenge that DR and Sitecore Commerce feels like a mythical Phase 5 of a project with only 4 Phases.
I want to write-up some notes and exploratory digging I did recently on the topic of disaster recover and Sitecore Commerce 8.2.1. You could even consider it a poor man’s option for database high availability that doesn’t incur the licensing costs of SQL Server Always On . . . but it’s probably best if you forget I ever mentioned that. Just because something can be done, doesn’t mean it should be done. I get in trouble sometimes presenting cans when I should just stick to the shoulds, but sometimes there’s real opportunity in those cans so I just can’t resist. Reader: beware.
Enough preamble. To simplify the scope of this post, I’m going to focus on database disaster recovery since it’s distinct for Sitecore Commerce 8 from “regular” Sitecore without Commerce. It’s because Commerce has a decade (or two!?) of COM code and legacy architectures that are way down deep in the Sitecore Commerce 8.2.1 system.
The crux of the challenge I was tasked with addressing was the inability to identify a SQL Mirror as part of a Sitecore Commerce 8.2.1 project. Many customers have used SQL Server database “Mirroring” as the high availability option for Sitecore databases for a long time because it was the only one officially supported by Sitecore. As this documentation explains, only since Sitecore 8.2 has “Always On” been an option for an officially supported Sitecore implementation. I know — many projects are successful with newer SQL Server approaches or RDS on AWS etc, but in my role at Rackspace, we have to walk the line of what Sitecore officially supports from top to bottom to ensure clean lines of escalation in the event of any issue; this is appealing to risk-averse customers, those with aggressive SLAs, etc.
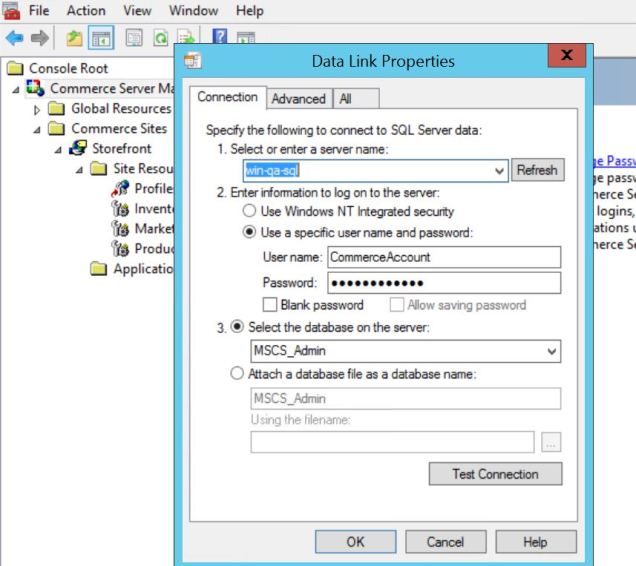
To use SQL Server Mirroring one must identify a failover partner in each of your SQL Server database connections defined in ConnectionStrings.config like:

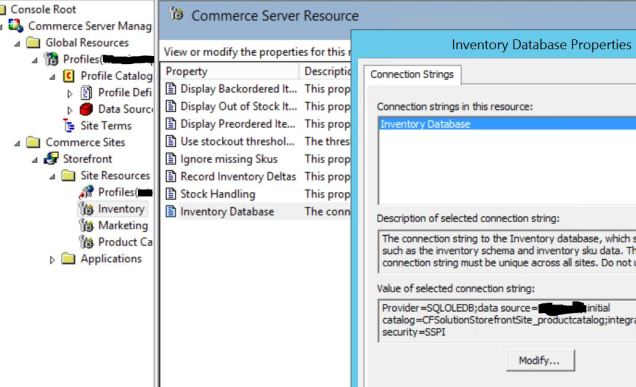
In Sitecore Commerce 8.2.1, however, this is the interface you have to manage a database connection for the MSCS_Admin database . . . there is a single endpoint (server name) and no provision for a failover partner. It comes down to a limit of the SQLOLEDB.1 provider, I believe. It’s fine for a SQL Server Availability Group listener where you get a service to route requests between the Always On SQL Server nodes, but this Commerce UI is incompatible with SQL Server Database Mirroring:
I set to digging and found some old documentation on a Windows Registry key for Commerce Server 2007 edition and the MSCS_Admin database. I’ll assume you understand the primacy of the MSCS_Admin database for Sitecore Commerce 8.2.1 — if that’s not the case, you can review this material for background, but trust when I explain that MSCS_Admin is the administrative heart of Sitecore Commerce 8.2.1. This SQL query shows how the ResourceProps table in MSCS_Admin stores all the dependent database connections for Inventory, Catalog, Profiles, etc:

Now, the old documentation I found mentions an encrypted registry key named ADMINDBPS that is where Commerce Server Manager, the desktop tool, reads and writes the actual database connection string for the MSCS_Admin database. Since I can’t insert a DB Mirroring Failover Partner into the desktop tool, I figured I could engineer a work around using this registry key as leverage.
The problem, however, is this documentation I was reading was from 2006 and no longer reflected reality. It also mentioned how this approach wasn’t supported by Microsoft and came with every cautionary disclaimer. Sounds like fun, right? The Windows Registry Key schema had changed, but not the overall approach and after doing some digging I found HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\CommerceServer was where this newer version of Sitecore Commerce had reorganized the Registry state and that’s where ADMINDBPS was hiding!
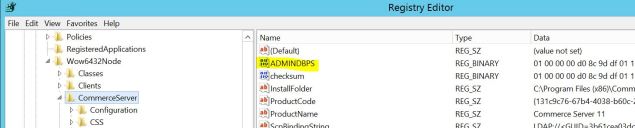
The connection string to MSCS_Admin was still encrypted . . . sure . . . but nothing the .Net System.Security.Cryptography namespace couldn’t resolve.
The connection string to MSCS_Admin was still buried in the Windows Registry . . . sure . . . but nothing the .Net Microsoft.Win32 namespace couldn’t resolve.
Here’s the code I used to read this value:
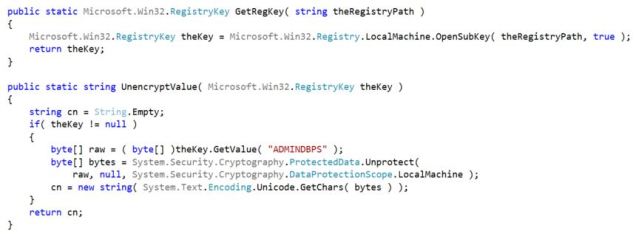
Since we’re getting this value, we might as well just add the set logic too, right?

Yes, let the Registry edits flow through you!
I told you this was a reader: beware type of post.
Taking a step back, remember my original challenge was finding a way to weave support for SQL Server DB Mirroring into Sitecore Commerce 8.2.1 and I found the MSCS_Admin database connection to be my focus? We can wrap the above c# code into a command line tool that can be run in a database failover situation to update the MSCS_Admin database connection automatically — changing to the intended failover partner defined as part of the conventional SQL Server Database Mirroring. We could schedule this c# logic to run once every 30 seconds in Windows Task Scheduler, for example, conditionally changing the MSCS_Admin database connection in the event of a failover scenario. The MSCS_Admin database connection string could update automatically. I’m not going to present this as a viable alternative to SQL Server Always On for many many reasons, but you achieve some semblance of it with robust enough PowerShell.
If you’re scratching your head here because I work with customers who are risk averse or have critical Sitecore SLAs that would still rely on the above Registry hacks, you’re not quite getting my point. I’m sharing this because it’s possible, it’s interesting to know how the guts of Sitecore Commerce 8.2.1 are working, and others may also learn from this. While it’s theoretically an option to introduce some automated failover logic through this method, it’s an uncomfortable hack. Based on my testing, though, it works.
Honestly, this technique is most appropriate in a disaster recovery scenario where a set of database servers are unavailable (and then this can apply whether using SQL Server Always On or DB Mirroring — doesn’t really matter). Instead of considering this a high availability solution, it’s a DR solution.
I spoke with some on the Sitecore Commerce technical team about this and they agreed this was a bit crazy, but it works (and also I shouldn’t quote them directly). They also pointed out how you don’t have to store MSCS_Admin connections in the Windows Registry and that as part of the PaaS support evolving through Sitecore Commerce there was a “Registry Free” deployment option for Sitecore Commerce 8.2.1 that I didn’t know about for this version. With this technique, you can use a ConnectionString defined like the others for Sitecore (see some details here)
<connectionStrings>
<add name="ADMINDBPS" connectionString="<your MSCS_Admin connection string" />
</connectionStrings>
I haven’t experimented with the Registry Free deployment for Commerce 8.2.1 but I’d like to see if it avoids the tyranny of the SQLOLEDB.1 provider and would let us add the Failover Partner logic to a connection string. I think this blog post may have a Part 2 . . . but I’m not sure how much further down this rabbit hole it’s worth tunneling.