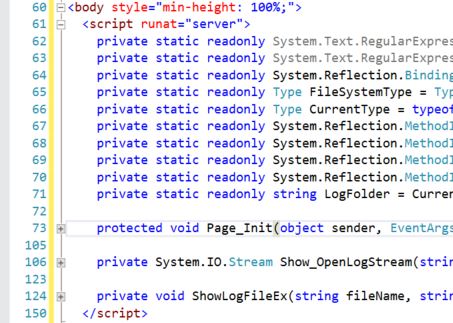
I’ve consulted with a number of Sitecore implementations in the last month or two that had a variety of challenges with Sitecore integration with Solr. Solr is a powerful distributed system with a variety of angles of interest to Sitecore. I wanted to take this chance to comment on a Sitecore setting that can have a significant impact on how Sitecore search functions, but is easily overlooked. The setting is defined in Sitecore.ContentSearch.config and it’s called ContentSearch.SearchMaxResults. The XML comment for this setting is straight-forward, here’s how it’s presented in that file:

There’s a lot to digest in that xml comment above. One could read it and assume “this can be set but it is best kept as the default” means this shouldn’t be altered, but in my experience that can be problematic.
The .Net int.MaxValue constant is 2,147,483,647. If you leave this setting at the default (so “”), one is telling Solr to return up to 2,147,483,647 results in a single response to a query, which we’ve observed in some cases to cause significant performance problems (Solr will fetch the large volume of records from disk and write them to the Solr response causing IO pressure etc.) It’s not always the case since it really comes down to the number of documents one is querying from Solr, but this sets up the potential for a virtually unbounded Solr query.
It’s interesting to trace this setting through Sitecore and into Solr, and it sheds light on how these two complex systems work together. Fun, right!? I cooked up the diagram below that shows an overview of how Sitecore and Solr work together in completing search queries:

Each application has it’s own logging which will help trace activity between the systems.
The Sitecore ContentSearch Provider for Solr relies on Solr.Net for connectivity to Solr. It’s common for .Net libraries to copy their open source equivalents from the Java world (like Log4J has a .Net port for logging named Log4net, Lucene has a .Net port for search called Lucene.Net, etc). Solr.Net, however, is not a port of the Solr Java application to .Net. Instead, Solr.Net is a wrapper for the main Solr API elements that can be easily called by .Net applications. When it comes to Sitecore’s ContentSearch Provider for Solr, Solr.Net is Sitecore’s bridge for getting data to and from the Solr application.
Just an aside: some projects do creative things with Solr search and Sitecore, and for certain scenarios it’s necessary to bypass Solr.Net and use the REST API directly from Sitecore. This write-up focuses on a conventional Sitecore -> Solr.Net -> Solr pattern, but I wanted to acknowledge that it’s not the only pattern.
Tracking ContentSearch.SearchMaxResults in Sitecore
On the Sitecore side, one can see the ContentSearch.SearchMaxResults setting in the Sitecore logs when you turn up the diagnostics to get more granular data; this isn’t a configuration that’s recommended for using beyond a discrete troubleshooting session as the amount of data it can generate can be significant . . . but here’s how you dial up the diagnostic data Sitecore reports about queries:
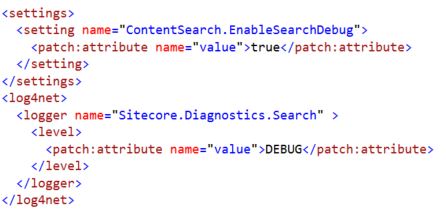
If you run a few queries that exercise your Sitecore implementation code that queries Solr, you can review the contents of the Search log in the Sitecore /data directory and find entries such as:
INFO Solr Query – ?q=associated_docs:(“\*A5C71A21-47B5-156E-FBD1-B0E5EFED4D33\*”)&rows=2147483647&fq=_indexname:(domain_index_web)
or
INFO Solr Query – ?q=((_fullpath:(\/sitecore/content/Branches/ABC/*) AND _templates:(d0351826b1cd4f57ac05816471ba3ebc)))&rows=2147483647&fq=_indexname:(domain_index_web)
The .Net int.MaxValue 2147483647 is what Sitecore, through Solr.Net, is specifying as the number of rows to return from this query. For Solr cores with only a few hundred results matching this query, it’s not that big a deal because the query has a fairly small universe to process and retrieve. If you have 100,000 documents, however, that’s a very heavy query for Solr to respond to and it will probably impact the performance of your Sitecore implementation.
Tracking ContentSearch.SearchMaxResults in Solr
Solr has it’s own logging systems and this 2147483647 value can be seen in these logs once Solr has completed the API call. In a default Solr installation, the logs will be located at server/logs (check your log4j.properties file if you don’t know for sure where your logs are being stored) and you can a open up the log and scan for our ContentSearch.SearchMaxResults setting value. You’ll see entries such as:
INFO – 2018-03-26 21:20:19.624; org.apache.solr.core.SolrCore; [domain_index_web] webapp=/solr path=/select params={q=(_template:(a6f3979d03df4441904309e4d281c11b)+AND+_path:(1f6ce22fa51943f5b6c20be96502e6a7))&fl=*,score&fq=_indexname:(domain_index_web)&rows=2147483647&version=2.2} hits=2681 status=0 QTime=88
- The above Solr query returned 2,681 results (hits) and the QTime (time elapsed between the arrival of the query request to Solr and the completion of the request handler) was 88 milliseconds. This is probably no big deal as it relates to the ContentSearch.SearchMaxResults, but you don’t know if this data will increase over time…
INFO – 2018-03-26 21:20:19.703; org.apache.solr.core.SolrCore; [domain_index_web] webapp=/solr path=/select params={q=((((include_nav_xml_b:(True)+AND+_path:(00ada316e3e4498797916f411bc283cf)))+AND+url_s:[*+TO+*])+AND+(_language:(no-NO)+OR+_language:(en)))&fl=*,score&fq=_indexname:( domain_index_web)&rows=2147483647&version=2.2} hits=9 status=0 QTime=16
- The above Solr query returned 9 results (hits) and the QTime was 16 milliseconds. This is unlikely a problem when it comes to ContentSearch.SearchMaxResults.
INFO – 2018-03-26 21:20:19.812; org.apache.solr.core.SolrCore; [domain_index_web] webapp=/solr path=/select params={q=(_template:(8ed95d51A5f64ae1927622f3209a661f)+AND+regionids_sm:(33ada316e3e4498799916f411bc283cf))&fl=*,score&fq=_indexname:(domain_index_web)&rows=2147483647&version=2.2} hits=89372 status=0 QTime=1600
- The above Solr query returned 89,372 results (hits) and the QTime was 1600 milliseconds. Look out. This is the type of query that could easily cause problems based on the Sitecore ContentSearch.SearchMaxResults setting as the volume of data Solr is working with is getting large. That query time is already climbing high and that’s a lot of results for Sitecore to require in a single request.
The impact of retrieving so many documents from Solr can cause a cascade of difficulties besides just the handling of the query. Solr caches the query results in memory and if you request 1,000,000 documents you could also be caching 1,000,000 million documents. Too much of this activity and it can stress Solr to the breaking point.
Best Practices
There is no magic value to set for ContentSearch.SearchMaxResults other than not “”. General best practice when retrieving lots of data from most any system is to use paging. It’s recommended to do that for Sitecore ContentSearch queries, too. A general recommendation would be to set a specific value for the ContentSearch.SearchMaxResults setting, such as “500” or “1000”. This should be thoroughly tested, however, as limiting the search results for an implementation that isn’t properly using search result paging can lead to inconsistent behavior across the site. Areas such as site maps, general site search, and other areas with implementation logic that could assume all the search results are available in a single request deserve special attention when tuning this setting.
What About Noisy Solr Neighbors?
I’ve worked on some implementations where Solr was a resource shared between a variety of Sitecore implementations. One project, in this example, might set ContentSearch.SearchMaxResults to “2000” for their Sitecore sites while another project sets a value of “500” – but what if there’s a third organization making use of the same Solr resources and that project doesn’t explicitly set a value for ContentSearch.SearchMaxResults? That one project leaves the setting at the “” default, so it uses the .Net int.MaxValue. This is a classic noisy neighbor problem where shared services become a point of vulnerability to all the consuming applications. The one project with “” for ContentSearch.SearchMaxResults could be responsible for dragging Solr performance down across all the sites.
Solr is an extensible platform much like Sitecore, and in some ways even more so. In Sitecore one extends pipelines or overrides events to achieve the customizations you desire; the same general idea can be applied to Solr – you just use Java with Solr instead of C#.
In this case, our concern being unbounded Solr queries, we can use an extension to a search component (org.apache.solr.handler.component.SearchComponent) to introduce our custom logic into the Solr query processing. In our case, we want to enforce limits to the number of rows a query can request. This would be a safety net in case an un-tuned Sitecore implementation left a ContentSearch.SearchMaxResults setting at the default.
Some care must be taken in how this is introduced into the Solr execution context and where exactly the custom logic is handled. This topic is all covered very well, along with sample code etc, at https://jorgelbg.wordpress.com/2015/03/12/adding-some-safeguard-measures-to-solr-with-a-searchcomponent/. For an enterprise Solr implementation with a variety of Sitecore consumers, a safety measure such as this could be vital to the general stability and perf of the platform – especially if one doesn’t have control over the specific Sitecore projects and their use (or abuse!) of the ContentSearch.SearchMaxResults setting. Maybe file this under best practices for governing Sitecore implementations with shared Solr infrastructure.