Sitecore’s Publishing Service that runs on .NET Core is a great addition to the Sitecore ecosystem. It allows us to solve some interesting customer scaling challenges by using this micro-services approach to Publishing content. I’m going to write-up a pattern we’re using these days that updates our approach from a few years ago.
See an example of the older pattern in this piece I wrote for the Rackspace site at https://developer.rackspace.com/blog/Sitecore-Enterprise-Architecture-For-Global-Publishing/.
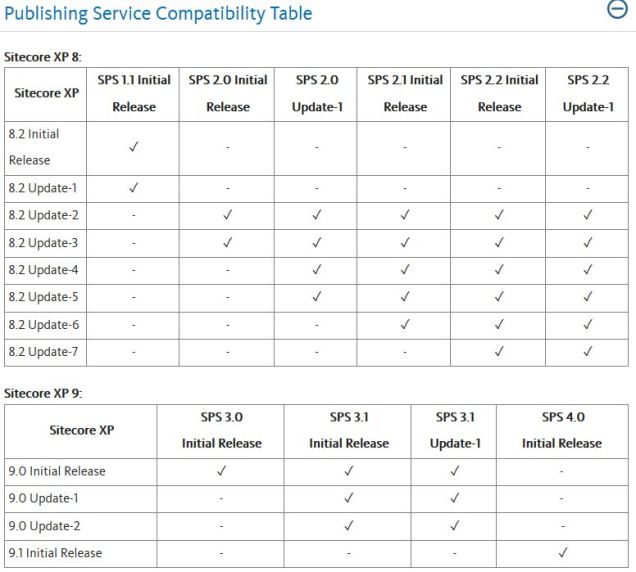
Now in May 2019, we’re shifting away from the SQL replication game and using Sitecore’s new Publishing Service to connect Sitecore across multiple regions. Refer to this general diagram below to see how we’re approaching it:
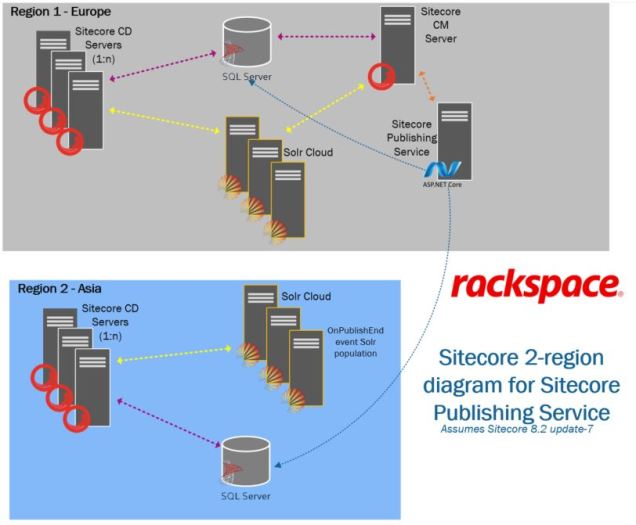
Sitecore’s Publishing Service is the key element between the two regions and the blue arrows show the flow of publishing activities coordinated through the one “Sitecore Publishing Service” host in Region 1.
A few caveats on the picture above:
- It’s Sitecore 8.2, so MongoDB is present but not shown on the diagram for simplicity (we use ObjectRocket’s hosted MongoDB service for the majority of these types of customers — but I don’t want to get into that here); Redis and other elements are also not included in the diagram
- This applies for any multi-region setup with Sitecore. . . it could be East US and West US, for example, but we used Europe and Asia in the diagram. This approach is most useful where network latency between the regions is enough to make synchronous database connectivity unacceptably slow. This model can apply to more than 2 regions, too, as the pattern can be repeated to support as many regions as you require.
There are just a few crucial configuration steps to make this happen, but it’s built on a lot of lessons learned along the way. Let me catalog the key elements:
- The Publishing Service runs in Region 1, but requires a Sitecore Publishing Target to the Region 2 database. The documentation on setting up this type of Publishing Target is vague, so I summarized this process at https://grantkillian.wordpress.com/2018/12/17/how-i-add-custom-sitecore-publishing-service-targets/.
- Each region has an isolated Solr cluster (because Solr CDCR or file synchronization for Solr were not suitable in this use-case). This means one of the Region 2 Sitecore CD servers needs to employ the onPublishEndAsync strategy to update the Solr Cloud collections relevant to the implementation. This is standard ContentSearch configuration material, but if you use the manual strategy here with the CDs (which is the general best practice for Sitecore CD servers connected to a Solr cluster with a CM that drives search indexing), the Solr data will never get updated in the other region:
-
<strategies hint="list:AddStrategy"> <strategy ref="contentSearch/indexConfigurations/indexUpdateStrategies/onPublishEndAsync"/> </strategies>
-
- If you are using Sitecore ContentTesting with this approach (<setting name=”ContentTesting.AutomaticContentTesting.Enabled” value=”true” />), you should be aware that Sitecore CM performance can occasionally stall for several minutes (we’ve seen it last up to 20 minutes!) due to an aspect of the ContentTesting logic that checks every content database for eligible published items to factor into the content testing system. Part of setting up the Region 2 Publishing Target involves adding a ConnectionStrings.config entry to the Region 2 “web” database on the Region 1 Sitecore CM server. This adds the Region 2 “web” database into this ContentTesting routine, and the network latency between Region 1 and Region 2 makes this ContentTesting behaviour slow the CM to a crawl every so often. If you don’t want to disable Sitecore ContentTesting, you can address this by customizing the Sitecore.ContentTesting.Helpers.VersionHelper.GetLatestPublishedVersion method to employ logic to exclude the Region 2 “web” database. Once you dig deep into this topic, you’ll see the Sitecore.ContentTesting.Helpers.VersionHelper class contains this logic and it’s used in 3 places (according to the decompilation of the .dll):
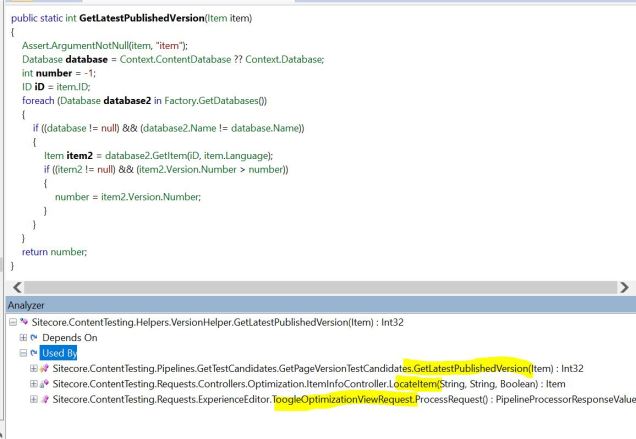
To adjust ContentTesting to ignore our Region 2 “web” database, we can alter the foreach loop above with something like this that uses a custom “ContentTesting.IgnoredDatabases” setting:
foreach (Database db in Factory.GetDatabases())
{
string[] excludeList =
Sitecore.Configuration.Settings.GetSetting(
"ContentTesting.IgnoredDatabases")
.ToLowerInvariant().Split(
new char[1]
{
'|'
},
StringSplitOptions.RemoveEmptyEntries);
if (database != null &&
db.Name != database.Name &&
!excludeList.Contains(db.Name))
{
Item item2 = db.GetItem(item.ID, item.Language);
if (item2 != null && item2.Version.Number > num)
{
num = item2.Version.Number;
}
}
}
We can define our custom setting like the following, if we assume region2web is the “web” database ConnectionString name for the Region 2 publishing target on the Sitecore CM:
<configuration xmlns:patch="http://www.sitecore.net/xmlconfig/">
<sitecore>
<settings>
<setting name="ContentTesting.IgnoredDatabases">
<patch:attribute name="value">core|region2web</patch:attribute>
</setting>
</settings>
</sitecore>
</configuration>
This work to override the default configuration from . . .
<getVersionedTestCandidates>
<processor
type="Sitecore.ContentTesting.Pipelines.GetTestCandidates.GetPageVersionTestCandidates, Sitecore.ContentTesting">
. . . can dramatically improve the Sitecore CM performance when using this formula for multi-region Sitecore with the new Publishing Service.
Hopefully these notes help other efforts on their Sitecore journey!